Data pasien sakit jantung yang di dapat dari Kaggle.com di olah untuk mengklasifikasikan data nya sehingga mendapatkan metode yang paling baik menggunakan machine learning.
langkah pertama, cari lah sebuah dataset atau sekumpulan data yang didapatkan dari Kaggle.com sebagai bahan untuk mengklasifikasikan data yang diolah dengan menggunakan machine learning. Dalam kesempatan kali ini, digunakan dataset heart atau sebuah sataset yang menyimpan sekumpulan data pasien sakit jantung dengan berbagai kondisi dan keadaan yang dijelaskan sebagai berikut:
Age : Age of the patient
Sex : Sex of the patient
exang: exercise induced angina (1 = yes; 0 = no) ca: number of major vessels (0-3)
cp : Chest Pain type chest pain type
Value 1: typical angina
Value 2: atypical angina
Value 3: non-anginal pain
Value 4: asymptomatic
trtbps : resting blood pressure (in mm Hg)
chol : cholestoral in mg/dl fetched via BMI sensor
fbs : (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
rest_ecg : resting electrocardiographic results
Value 0: normal
Value 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV) Value 2: showing probable or definite left ventricular hypertrophy by Estes' criteria
thalach : maximum heart rate achieved
target : 0= less chance of heart attack 1= more chance of heart attack
Setelah dataset di unduh, maka buka google colaboratory dan buat file baru, kemudian importkan modul yang dibutuhkan seperti berikut:

Setelahnya, lakukan pengecekan data seperti berikut:

Dapat juga digunakan grafik agar lebih mudah mengecek datanya.


Target dari variabel kemudian ditampilkan yang dibagi menjadi 2, beresiko atau tidak dan dilihat apakah keduanya seimbang.


Selanjutnya ditampilkan fitur continu nya.


Ditampikan juga untuk fitur yang berjenis kategorikal.


Dari grafik, disimpulkan bahwa wanita dinilai lebih banyak menderita sakit jantung. Selanjutnya akan ditampilkan korelasi dan informasi yang mutual atau sejenis.


Korelasi juga dapat di eksplorasi dengan mencari diantara fiturnya.


Data selanjutnya dipisah untuk di test yang dimulai dengan preprocessing dan kemudian dilakukan model training untuk mengetesnya menggunakan beberaa metode.


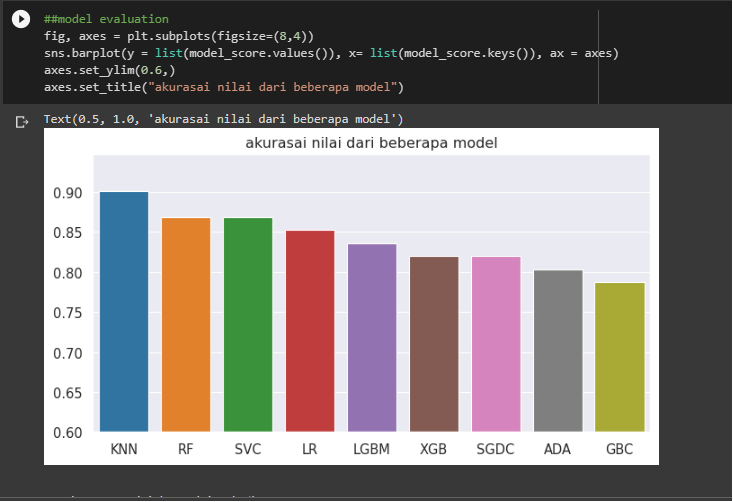
Setelah itu maka data akan dievaluasi dan ditampilkan melalui grafik untuk melihat akurasi dari beberapa modelnya.

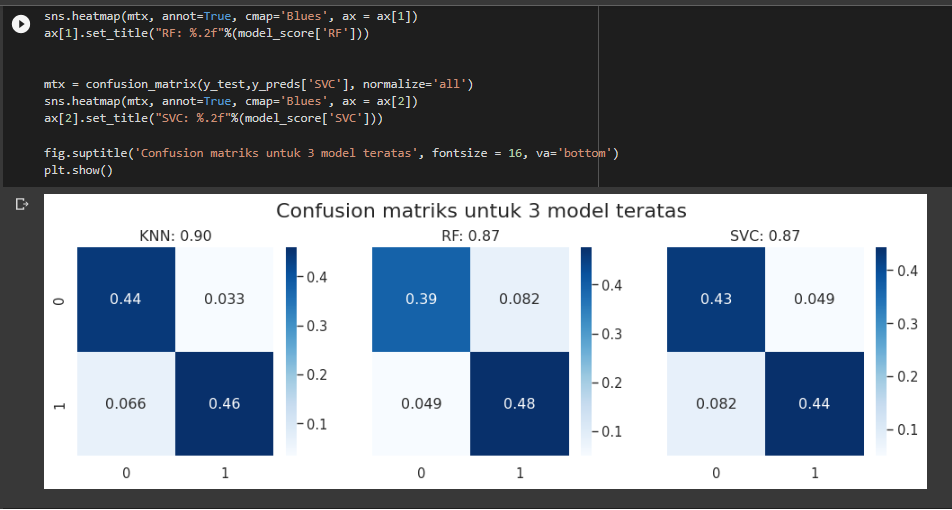
Selain itu juga ditampilkan confusion matrik untuk menampilkan 3 model dengan akurasi teratas.

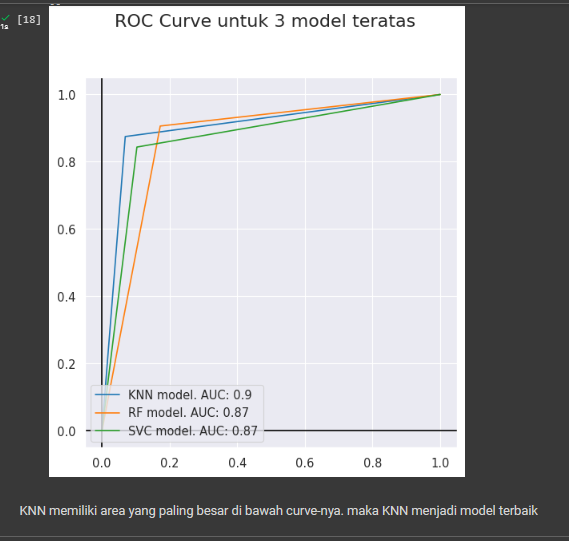
Terakhir juga dibuat penggambaran grafik ROC curve untuk mencari model terbaik dan disimpulkan bahwa KNN menjadi metode terbaik karena tingkat akurasinya tertinggi mencapai 0,9.